【技術ブログ】弊社で運用している生活記録アプリ フロントエンド API
みなさん、こんにちは。今回は技術的な記事になります。
筆者はアプリ開発チームに所属する利用者です。
弊事業所 STOVE において開発、社内運用されている生活記録アプリの技術スタックについて、開発者視点でつづらせていただきます。
以下の記事で、簡易的な技術スタックについては触れられています。
この記事では、より深いところに触れていきたいと思います。
対象読者
- プログラミングの知識がある
- コンテナ技術、主に Docker の知識がある
- フレームワークやライブラリなどに関する知識がある
フロントエンドで利用している技術
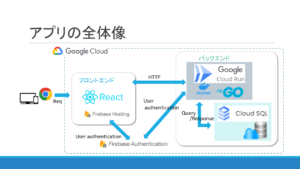
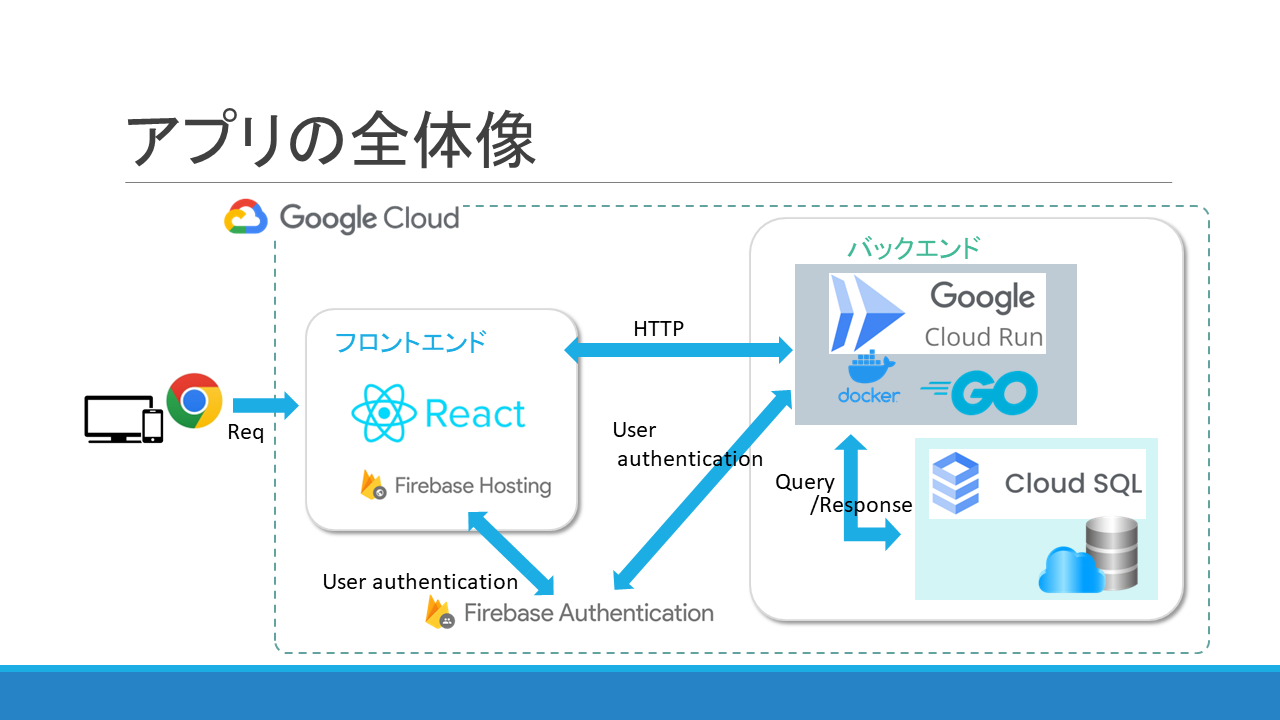
前回の記事で触れた通り、フロントエンドは React + Vite + TypeScript で構成されています。
今回は主に API サーバーとの通信について書いていきます。
Redux Toolkit を活用した通信
API サーバーとの通信には、RTK(Redux Toolkit)の RTK Query を使用しました。
RTK は Redux をよりかんたんに扱うためのツールキットです。
状態のメモ化に必要な reselect や非同期処理ができる redux thunk のようなライブラリを、一つにまとめた便利パックみたいなものです。
この便利パックの中に API 通信をするための API スライスを定義するための関数が入っています。それが RTK Query です。
RTK Query はキャッシュやエラーハンドリング、非同期通信の簡素化ができ、開発効率の向上を目指すことができます。
データの取得と送信
HTTP リクエスト処理には createApi を使用しています。
createApi の公式ページは以下になります。
ソースコードは主に以下のようになっています。(一部省略しています)
const userApi = createApi({
reducerPath: 'userApi',
tagTypes: ['Users'],
baseQuery: fetchBaseQuery({
baseUrl: `${env.API_HOST}/api/users/`,
// Headerに情報が必要であれば設定
// 今回は Redux Store に格納している idToken を渡している
prepareHeaders: (headers, { getState }) => {
const { idToken } = (getState() as RootState).authSlice
headers.set('accept', 'application/json')
if (idToken) {
headers.set('Authorization', `${idToken}`)
}
return headers
},
mode: 'cors'
}),
endpoints: (builder) => ({
// カナ順で削除済みを含む利用者権限のユーザーを全て取得する
getUsersWithDeletedNormalized: builder.query<EntityState<User>, void>({
query: () => 'with/deleted',
// Query の実行後、結果を返す前にデータを加工
transformResponse: (response: User[]) =>
// 正規化
userAdapter.setAll(userAdapter.getInitialState(), response),
}),
addUser: builder.mutation<User, Partial<User>>({
query(body) {
return {
url: `create`,
method: 'POST',
body
}
},
})
})
})この場合、 /api/users/with/deleted にリクエストすれば論理削除済を含むユーザー一覧が取得できて、 /api/users/create にリクエストすれば、新しいユーザーを作成することができる、という作りとなっています。
サーバーは idToken からユーザーを特定できます。なのでヘッダ情報として idToken を送付し、ユーザーを追加する権限があるか、そもそもログインしているかなどを確認しています。idToken に問題がなければ、リクエストに応じてデータベースを操作したりして、クライアントはその結果を受け取ります。
このシステムでは「利用者」「スタッフ」「管理者」の3つに分類された権限を持ったユーザーが作成できます。そのうち、ユーザー作成の権限は、管理者のみが持っています。
ログイン時に発行された idToken を毎リクエストごとに送付し、サーバー側でユーザーがどの権限なのか確認しているということです。
createApi で記述すると、自動的にカスタムフックが作成されます。
例えば今回の場合、 getUsersWithDeletedNormalized と addUser を作成しています。この2つの場合、useGetUsersWithDeletedNormalizedQuery と useAddUserMutation というカスタムフックが用意されます。
このカスタムフックを使うことで、API を通してサーバーと通信を実現しているというわけです。
取得データの正規化
また、RTK Query によって取得した JSON は createEntityAdapter で正規化して使っています。
createEntityAdapter の公式ページは以下のとおりです。
createEntityAdapter | Redux ToolKit
ソースコードは以下のような感じです。
たとえば本来 user_id 順に並んでいるユーザー一覧をカナ順にソートできるようにしています。
// 正規化用のアダプターを自動作成
const userAdapter = createEntityAdapter<User>({
// 正規化に使う id を UserId に設定
selectId: (user) => user.UserId,
// カナ順でソート
sortComparer: (a, b) => a.UserKana.localeCompare(b.UserKana, 'ja')
})正規化することで、データの深いネストや重複がなくなり、フラットな構造になります。
筆者が感じている最も大きなメリットとしては、配列をそのまま扱う際のデメリットが軽減されることです。
配列をそのまま扱う場合、特定の値が一つだけであったとしても、ループ構文で配列全体を探さなければ目的の値を取り出すことができません。これにより、検索や更新の操作が非効率になりやすいです。
しかし、データを正規化することで、各アイテムに一意な id を付与し、配列全体をループせずに特定の id で直接検索できるようになります。これにより、操作が効率的になり、特定のアイテムへのアクセスが素早くできます。
const { data, isLoading } =
useGetUsersWithDeletedNormalizedQuery()
const users = data
// たとえば上記のユーザに関する検索をするとしたら、このような関数を作ることができます。
const getUserNameByUserId = useCallback(
(userId: EntityId) => users?.entities[userId]?.UserName,
[users]
)
// 使用時
// userId が 1 の人の名前を取得できます
const userName = getUserNameByUserId(1)もしデータが正規化されていなかった場合、配列のままでユーザーの名前を取得するとしたらまずは user_id から特定のネストを抽出し、そのアイテムの中にさらにネストされている名前を探して拾ってくる必要があります。
以下のような感じでしょうか。
const { data, isLoading } =
useGetUsersWithDeletedQuery()
const users = data
const getUserNameByUserId = useCallback(
(userId: number) => {
const user = users?.find(user => user.id === userId)
return user?.UserName
},[users])
// 使用時
// userId が 1 の人の名前を取得できます
const userName = getUserNameByUserId(1)find メソッドを使うということは、もしも配列の内容が500個あった場合、最大500回ループする必要があるということです。
データを正規化すると、各アイテムに一意なIDをつけて、オブジェクト形式で管理することができます。これにより、find メソッドで配列全体を検索する必要がなくなり、ドット記法で ID を使って直接データにアクセスできるため、パフォーマンスが向上します。
大規模なデータでも無駄なくアクセスできて、コードもシンプルになります。正規化は、パフォーマンスと可読性の両方で大きなメリットがあるということですね。
しかも createEntityAdapter を使えば、正規化されたデータを扱うための様々な Reducer が自動で提供されるみたいです。(今回使われているものでいうと、selectAll など)
しかしこれに関してはこのシステムではあまり使っていません。
取得データの絞り込みはフロントエンドに寄せている
データベース内の情報の絞り込みに関しては、SQL の JOIN などを駆使して、画面に合わせた API URL を都度作成するという方法のほうが、SQL の強みを発揮できます。しかし、以下の5つの理由で一度に SQL から多めの情報を取得し、フロントエンド側で整理するように考えて作っていました。
まず根本の理由の一つとして、SQL や Go よりも、フロントエンドに慣れているメンバーが多かったからというものがあります。フロントエンドに処理を寄せることで、データの整形などの調整を、得意な言語で記述することができます。
ただそれ以外に、フロントエンド側にこの処理を寄せることで、上記のRTK Query の正規化やキャッシュ最大限活かすことができる点も重要な理由でした。
このアプリの API サーバーのデプロイは、以前の記事の通り、Google Cloud Run におこなっています。キャッシュが有効活用できるようになると、サーバーへのリクエスト回数が減り、Cloud Run の負担が軽減されます。Cloud Run は従量課金制なので、負荷がかからないように運用することで、コストが削減できるというこです。
その分クライアント側にしわ寄せがくることになりますが、一昔前と比較し、近年はクライアントのマシンパワーがあがっているため、サーバーではなくクライアント側に処理を寄せても、大きなデメリットとはならないと判断しました。